
今回は、完成したモデルの精度を検証していきます。
前回の記事はこちらから。

検証結果
1〜6号艇までモデルが6つあるので、今回は3号艇を中心に検証結果を見ていきます。まずは、このモデルで一番重要な、どのくらいの精度で1着率を当てることができたのかを見ていきます。
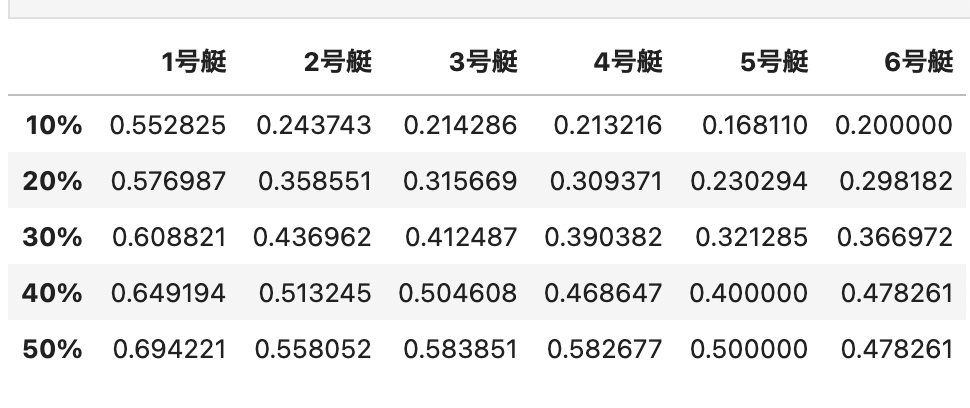
こちらが検証結果一覧です。列のパーセンテージは閾値で、例えば、3号艇の勝率30%以上と予測した場合の実際の勝率は約41.2%ということになります。
グラフにするとこんな感じ。当然閾値が上がるにつれて勝率も上がっています。
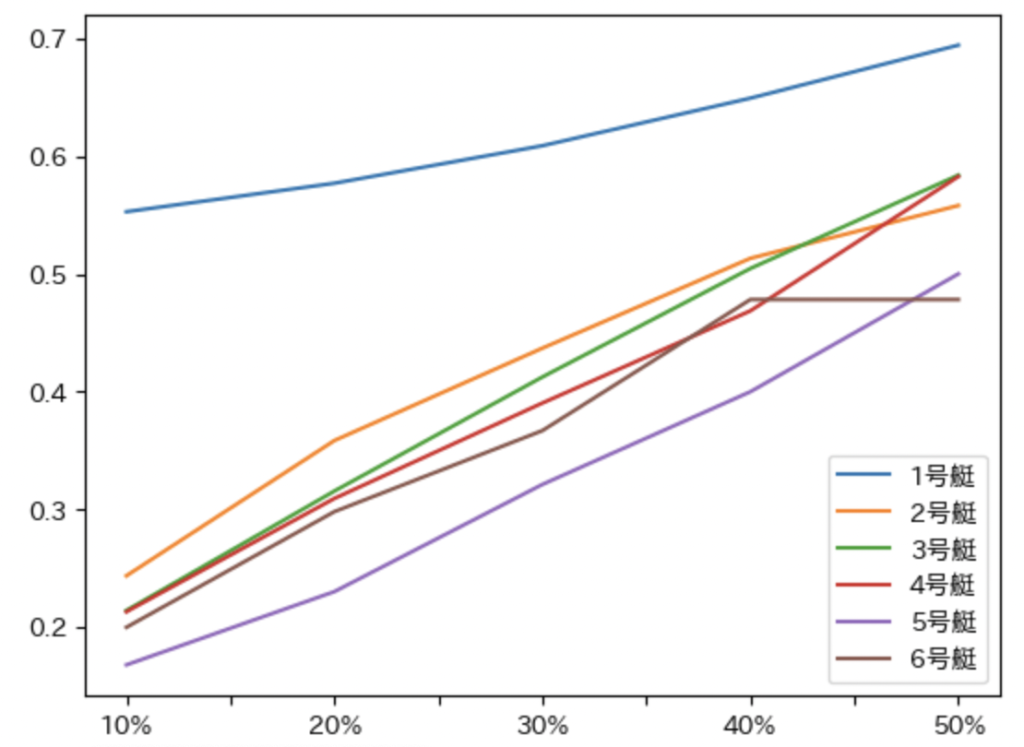
思いのほか、いや想像以上にいい感じ。
続いてsklearnのclassification_reportを使って評価指数を見ていくと
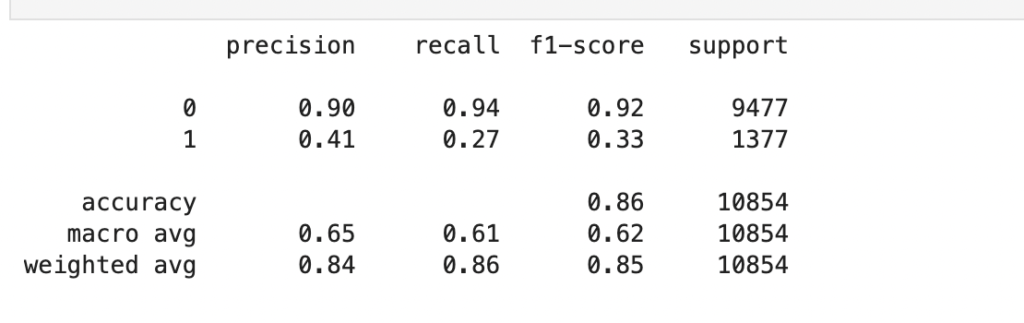
『1着と予想した選手が1着であること』が一番重要なので、今回のaccuracyが41%というのはいい結果と言えるんじゃないでしょうか。
recallがそれと比べると低く感じるけど、6艇で走る、不確定要素が多いことを考えればそんなものかという気もします。
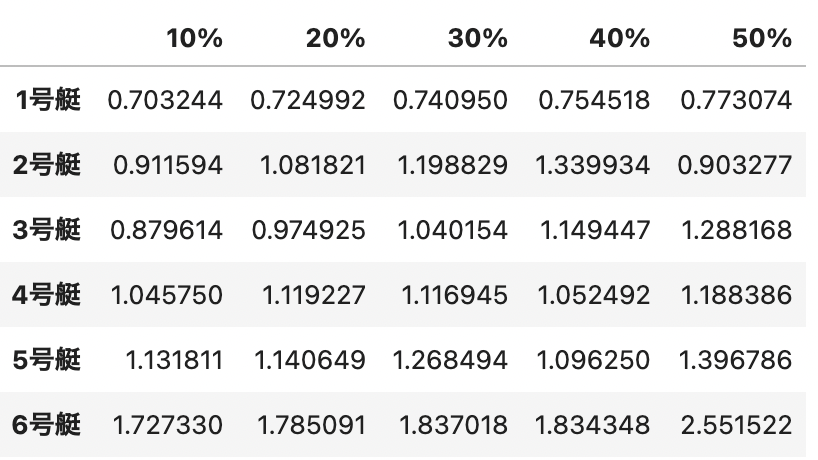
因みに、1ー全ー全とか、6ー全ー全とかで買った場合の回収率のシュミレーション結果はこんな感じです。例えば、3号艇の勝率30%以上と予測したレースを”3ー全ー全”で買い続ければ、104%の回収が見込めるということです。5号艇、6号艇買い続ければ儲かって仕方ないということです。
特徴量の重要度
次に、特徴量の重要度を見ていきます。feature_importanceではやはり予測する艇の1着率が一番大事だということでした。(この場合、3枠の1着確率を予測したモデルです)
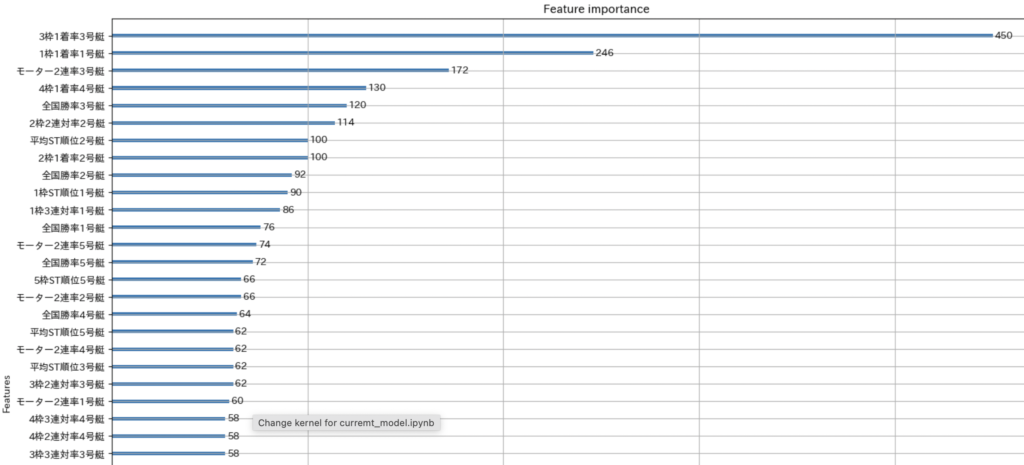
3枠1着率が一番重要なのは、当然の結果と言えますが、3枠2連帯率はだいぶ下の方で、1着率を予想する上での重要度が低いのは意外な結果でした。
そして、1枠1着率が2番目にあるのは、やはりボートレースはインコースVSアウトコースという構図が基本なのだと改めて感じる結果となりました。
これは罠なのか?
ここまでやってきて思った。こんなうまい話あっていいのかと。どこかに間違いがあるんじゃないかと。
割とあっさりと気づいてしまった。罠だったと。
それは、間接的にテストデータを学習データに使ってしまっていた事。
どういうことかというと、前回作ったcsvファイル

1着率とか2連対率というデータは、テストデータから作られたものが含まれているということです。テストデータからも”1枠1着率”などのデータが作られているということ。
そりゃ、6枠回収率高くなるよな笑。。
ただ、テストデータがトレーニングデータに寄っているという事であって、過学習しているとかいうことではないので、これで暫く運用してみることにします。
まとめ
苦労も多かったですが、とりあえず完成ということで一区切りとしたいと思います。
第一回から読んで下さった方ありがとうございました。まだという方はぜひそちらも楽しんでいただければと思います。
一区切りではありますが、ゴールではなく現在『果たしていくら儲かるのか』を実際に検証しており、結果報告も後日できればと思っております。
それと、AIを作ると同時に、ボートを予想するのに思わぬ副産物のような発見もあったので、それも記事にしたいと思ってますので、またお付き合いください。




