
こんにちは。
今回もスピンオフと言うことでボートレースを予想する上での、新しい予想ファクターを作ってみた話になります。
lightGBMでボートレース予想AIを作ってみたの番外編になります。
まだ本編見てないと言う方は是非こちらからどうぞ。

スピンオフ第一弾として『4角の峰は峰なのか』の検証もしてみたので、こちらも是非ご覧ください。

予想ファクター新概念データとは?今回の経緯
舟券買う方なら説明不要だと思いますが、『2コース逃し率』とか『2着傾向』とかのアレです。
もっと詳しく知りたいデータあるよなーと、ネット検索してみたけどそれらしい情報もなかったので、streamlitの勉強がてら自分で作っちゃえと言うのが今回の始まりです。
さっそく完成したアプリの完成形を公開
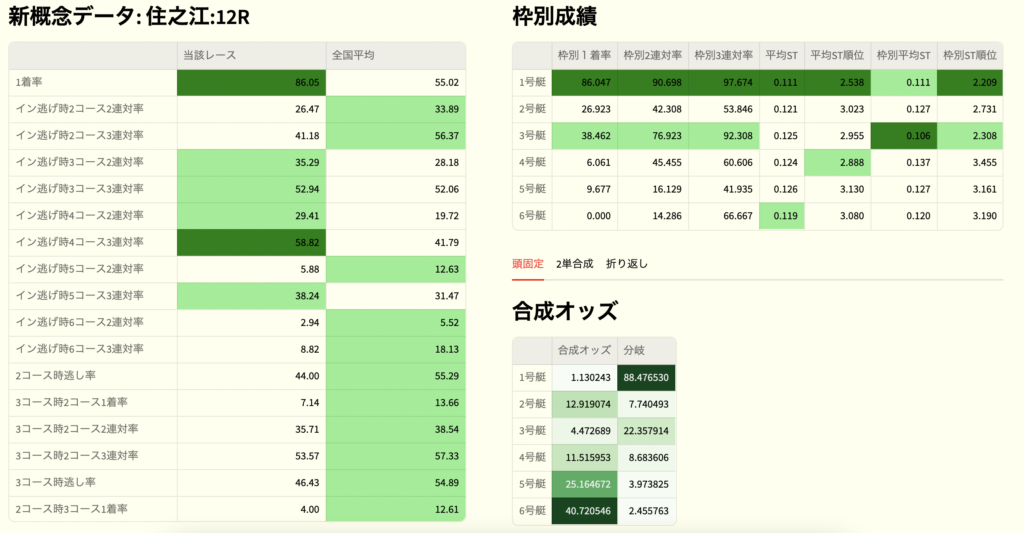
こちらが今回の完成形になります。
見切れていますが、上部にURL入力欄があり、予想対象レースのURLをコピー&ペーストで出走表とオッズを読み込み、ローカルにあるデータを参照して表示するような仕組みになってます。
もう見たままですが、画面左が今回のミソである『新概念データ』、右上が枠番別競争成績とスタート情報、右下が合成オッズとなります。
アプリケーションの仕組みは実にシンプルで、以下のようなフォルダ構成から
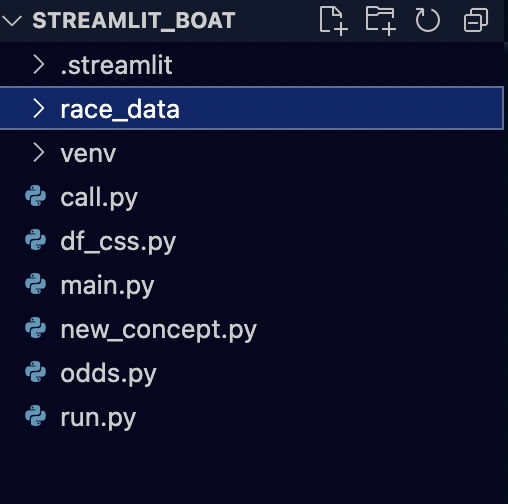
- 以前作った各選手の競争成績から、枠別1着率だったり枠別平均スタートだったりをひたすら計算させた結果を”race_data”に入れておく
- URLからオッズデータを取得して合成オッズと、各枠番の期待値がプラマイゼロになる勝率の分岐点の計算
- run.pyの実行を合図に”race_data”から必要なデータを抽出して、②のオッズを計算の結果をstreamlitで表示する
と言う方法です。
ちなみに、ファイルを簡単に説明すると.streamlitがstreamlitの設定、venvは仮想環境設定、call.pyがデータの呼び出し、df_cssがデータフレームの色付け設定、main.pyがデータフレームの作成、new_conceptが①の計算ファイル、odds.pyがオッズデータの取得ファイル、run.pyが実行ファイルになります。
『この選手が4コースに入れば外枠が熱い』とか2コースと3コースの兼ね合いだったりもひと目で確認できますし、合成オッズと合わせてここは過剰人気、ここは過小評価されてるから狙いたいなどの可視化ができます。
課題
5艇立てのレースに対応できてない。
新人選手のインコース戦などの少ないデータへの信頼度が低い。
“race_data”の量が膨大なためgithubにアップロードできないので、ローカル環境でしか動かす方法がない(データベースの知識があればできそうですが全く無知なので)。
改善点も多いですが、こんな簡単にGUIが実装できると思いませんでした。tkinterでも試みてみましたが、こちらの方が使いやすかったですね。
せめてデータベースの問題がクリアできれば、公開してみんなにも使ってもらえるのにーとヤキモキしてます。
streamlit公式の解説も豊富なのでまだ使ったことない方、とりあえずなんか作ってみたいという方にはおすすめ。シンプルなコードで、結構カッコいいアプリケーション作れます😁
最後にstreamlitを動かすメインファイルのrun.pyを載せておきます。
import numpy as np
import pandas as pd
import streamlit as st
import main
import df_css as css
import re
import odds
st.set_page_config(layout="wide")
jyo_dic_r = {'01':'桐生','02':'戸田','03':'江戸川','04':'平和島','05':'多摩川','06':'浜名湖','07':'蒲郡','08':'常滑','09':'津',
'10':'三国','11':'びわこ','12':'住之江','13':'尼崎','14':'鳴門','15':'丸亀','16':'児島','17':'宮島','18':'徳山',
'19':'下関','20':'若松','21':'芦屋','22':'福岡','23':'唐津','24':'大村'}
head1,head2 = st.columns(2)
with head1:
url = st.text_input("url input")
btn = st.button('更新')
try:
try:
d = re.findall(r'\d+', url)
raceNo = (f'{jyo_dic_r[d[1]]}:{d[0]}R')
df1,df2 = main.analyze(url)
df1 = df1.style.apply(css.sabun, n=1, axis=1).apply(css.distance_10high,axis=1).format(precision=2)
df2 = df2.style.apply(css.st_average2,n=2 ,axis=0,subset=['平均ST','平均ST順位','枠別平均ST','枠別ST順位'])\
.apply(css.st_average1, n=1, axis=0,subset=['平均ST','平均ST順位','枠別平均ST','枠別ST順位'])\
.apply(css.rentairitsu2, n=2, axis=0,subset=['枠別1着率','枠別2連対率','枠別3連対率'])\
.apply(css.rentairitsu1, n=1, axis=0,subset=['枠別1着率','枠別2連対率','枠別3連対率'])\
.format(precision=3)
except:
pass
try:
df_odds,df_tan,df_bunki,df_2tan = odds.odds(url)
df_odds = df_odds.set_axis(['1号艇','2号艇','3号艇','4号艇','5号艇','6号艇'])
df_odds = df_odds.style.background_gradient(cmap='Greens')
df = pd.DataFrame(df_tan)
bunki = [((1/i)*100) for i in df_tan]
dfdetail = pd.DataFrame(df_bunki)
df.index=['1号艇','2号艇','3号艇','4号艇','5号艇','6号艇']
df.columns=['合成オッズ']
df['分岐 '] = bunki
df = df.style.background_gradient(cmap='Greens')
df_2tan = df_2tan.set_axis(['1号艇','2号艇','3号艇','4号艇','5号艇','6号艇'])
df_2tan = df_2tan.style.background_gradient(cmap='Greens')
except:
pass
col1, col2= st.columns(2)
with col1:
st.subheader(f"新概念データ: {raceNo}")
st.dataframe(df1 ,height=630,width=600,use_container_width=False)
with col2:
st.subheader("枠別成績")
st.dataframe(df2,width=350,use_container_width=True)
try:
tab1, tab2, tab3 = st.tabs(["頭固定", "2単合成", "折り返し"])
tab1.subheader("合成オッズ")
tab1.write(df)
tab2.subheader("合成オッズ")
tab2.dataframe(df_2tan,width=490)
tab3.subheader("合成オッズ")
tab3.dataframe(df_odds,width=490)
except:
pass
except:
pass基本的なファイルはこれだけでアプリケーションが作れて、公開できるなんてほんとに素晴らしいですね。
『ちょっとやってみたい!!』がこれほど手軽にできるので是非試してみてください。
それではまた。




