
こんにちわ。
今回は、pythonのライブラリであるmatplotlibを使って選手の強さを可視化できるようにチャレンジしてみます。
というかまたまたボートネタですんません。だって好きなんですもん✨ボートレースで勝てるようになりたいですもん。
ということでお付き合いください🙇♀️
実装コード
まず先に実装コードがこちら。
import os
import pandas as pd
import re
import itertools
from matplotlib.backends.backend_pdf import PdfPages
import matplotlib.pyplot as plt
import japanize_matplotlib
#出走表を読み込む
TXT_FILE_DIR = '/Users/tom/boat_pred/ai_predict/predict_run/data_txt_B/'
txt_file = os.listdir(TXT_FILE_DIR)
with open(f'/Users/tom/boat_pred/ai_predict/predict_run/data_txt_B/{txt_file[0]}', encoding='shift-jis') as f:
dataB = f.read()
dataB1 = dataB.split('BBGN')
date = '20'+txt_file[0][1:7]
st_da = pd.read_csv('/users/tom/boat_pred/rating/rating.csv')
data_list = []
lis = []
for b in dataB1[1:]:
bbb = b.split('\n')
racers = [row.replace('\u3000','').replace('\n','') for row in bbb if re.match('^[0-6]\s', row)]
pattern = '^([1-6])\s(\d{4})([^0-9]+)(\d{2})([^0-9]+)(\d{2})([AB]\d{1})\s(\d{1}.\d{2})\s*(\d+.\d{2})\s*(\d+.\d{2})\s*(\d+.\d{2})\s+\d+\s*(\d+.\d{2})\s*\d+\s*(\d+.\d{2})'
pattern_re = re.compile(pattern)
valueB1 = [re.match(pattern_re, racer).groups() for racer in racers]
code = re.search(r'\d+[BEND]',b[-19:]).group()[0:2]
#1レース毎に出走表
race_no = ['1','2','3','4','5','6','7','8','9','10','11','12']
valueB2 = [valueB1[i:i+6] for i in range(0, len(valueB1), 6)]
df_B = []
for i,n in zip(valueB2,race_no):
column = ['艇番', '選手登番', '選手名', '年齢', '支部', '体重', '級別', '全国勝率', '全国2連率', '当地勝率', '当地2連率', 'モーター2連率', 'ボート2連率']
sort_bangumi = pd.DataFrame(i,columns=column)
id=date+code+n
sort_bangumi['id'] = id
df_B.append(sort_bangumi)
##csv 型変換 to_csv
data = pd.concat(df_B)
data = data.reset_index(drop=True)
data["選手登番"] = data["選手登番"].astype('int')
num=data["選手登番"].values
df_race = [num[idx:idx + 6] for idx in range(0,len(num), 6)]
pdf = PdfPages(f"/users/tom/boat_pred/ai_predict/type2/power/{code}.pdf")
count=[0,1,2,3,4,5,6,7,8,9,10,11]
fig, axes = plt.subplots(nrows=6, ncols=2, figsize=(8, 18))
for i,n in zip(df_race,count):
q1=st_da[st_da['選手登番']==i[0]]
q2=st_da[st_da['選手登番']==i[1]]
q3=st_da[st_da['選手登番']==i[2]]
q4=st_da[st_da['選手登番']==i[3]]
q5=st_da[st_da['選手登番']==i[4]]
q6=st_da[st_da['選手登番']==i[5]]
df3 = pd.concat([q1,q2,q3,q4,q5,q6])
w1 = df3['1枠パワー'][:1].values[0]
w2 = df3['2枠パワー'][1:2].values[0]
w3 = df3['3枠パワー'][2:3].values[0]
w4 = df3['4枠パワー'][3:4].values[0]
w5 = df3['5枠パワー'][4:5].values[0]
w6 = df3['6枠パワー'][5:6].values[0]
x = [w1,w2,w3,w4,w5,w6]
y = df3['トータルパワー'].values
axes[n//2, n%2].set_title(f'{n+1}R')
axes[n//2, n%2].scatter(w1,y[0],c='grey',s=50,marker="D",alpha=0.7)
axes[n//2, n%2].scatter(w2,y[1],c='black',s=50,marker="D",alpha=0.7)
axes[n//2, n%2].scatter(w3,y[2],c='r',s=50,marker="D",alpha=0.7)
axes[n//2, n%2].scatter(w4,y[3],c='b',s=50,marker="D",alpha=0.7)
axes[n//2, n%2].scatter(w5,y[4],c='y',s=50,marker="D",alpha=0.7)
axes[n//2, n%2].scatter(w6,y[5],c='g',s=50,marker="D",alpha=0.7)
axes[n//2, n%2].set_ylabel('トータルパワー')
axes[n//2, n%2].set_xlabel('枠番パワー')
axes[n//2, n%2].grid(True)
axes[n//2, n%2].set_xlim(0, 650)
axes[n//2, n%2].set_ylim(0, 450)
fig.tight_layout()
pdf.savefig(fig)
pdf.close()
plt.close()今回の内容に関するとこは51行目のpdf…..のところからになります。
散布図でそれぞれの艇番の色ごとに[“枠番パワー”]と[“トータルパワー”]の交わる点を表示します。
表示したいのが一つだけなら以下のような感じでシンプルにできるのですが、
plt.scatter(x[0],y[0],c='grey',s=50,marker="D",alpha=0.7)
plt.scatter(x[1],y[1],c='black',s=50,marker="D",alpha=0.7)
plt.scatter(x[2],y[2],c='r',s=50,marker="D",alpha=0.7)
plt.scatter(x[3],y[3],c='b',s=50,marker="D",alpha=0.7)
plt.scatter(x[4],y[4],c='y',s=50,marker="D",alpha=0.7)
plt.scatter(x[5],y[5],c='g',s=50,marker="D",alpha=0.7)
plt.xlabel('枠パワー')
plt.ylabel('トータルパワー')
plt.xlim(0, 650)
plt.ylim(0, 450)
plt.grid(True)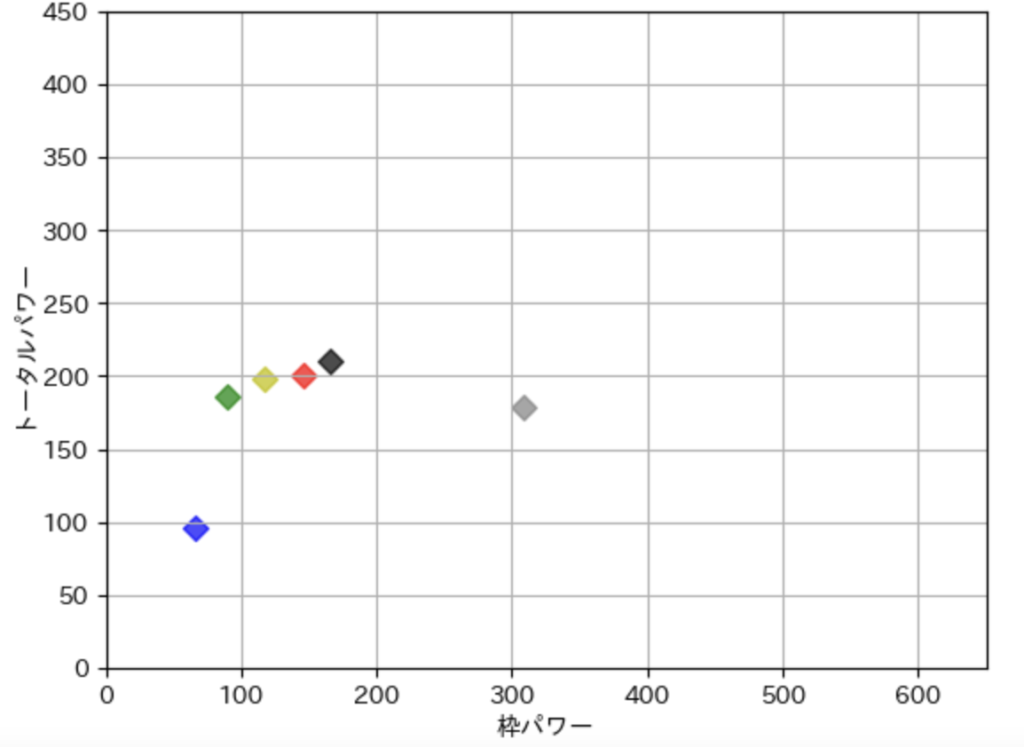
やりたかったことは『1日のレースすべて可視化して勝負レースを見定めること』なので1日の全ての開催場、全てのレースをforループを使ってplotしていきます。
pdf = PdfPages(f"/users/tom/boat_pred/ai_predict/type2/power/{code}.pdf")でPdfPagesをまずインスタンス化。そうインスタンス化です。なぜこんなまどろこしいインスタンス化する必要があるのか私も理解してませんが慣れてきました。
次に、
fig, axes = plt.subplots(nrows=6, ncols=2, figsize=(8, 18))
これでplotするための枠を作ります。データを入れる入れ物のようなイメージで良いかと思います。
nrowsとncolsでは、行数と列数を指定し、figsizeで縦横比を決めます。
1つのpdfファイルで1レース場、1レースから12レースを保存したいので、nrows=6、ncols=、2としました。
これを実行すると、
こんな感じでpdfファイル1ページに1場分、12レース分のパラメーターを保存することができました。
一応、見方としては上に行くほど選手能力が高い、右に行くほどその枠番での能力が高いということです。
余談ですが、選手の期別勝率って意外と当てにならなくて、SGやG1ばっか走ってる勝率7.00の選手と、一般戦がメインの選手の勝率7.00て大きく違いますからね。
なのでこの表は過去に走った“レースのレベル”、”どのレベルの選手と走ったのか”、も計算に入れて作ってます。一般戦の予選で1着取っても10点、SGで1着取っても10点なんておかしな話で価値が違いすぎますからね。
ループ処理で全レース場のpdfを取得
さらにこれを開催されている競艇場分ループさせることで、
全ての開催場のチャートを保存することができました。
ファイル名は以下のようにfストリングを使って開催場コードとしています。
07.pdfなら蒲郡、20.pdfなら若松ということですね。
最後に
axesにどうやって列番号と行番号を指示するかというのが課題でしたが、nの商、nの余の値を渡すことで、実装できました。
今回は以上です。
正直matplotlibって野暮ったく見えるし、なんかデザインがイケてないように感じてましたが、(今もそう思う)これだけ使われてるってことはやっぱり他のライブラリとの相性も良く、汎用性が高いんでしょうね。
以前streamlitでダッシュボードを作ったのですが、その時はオシャレという理由でplotlyを使いました。ただ、ちょっと不便にも感じて、なんというか痒いところに手が届かないというか、『惜しい』と思うことがあったような。それがなんだったかはもはや覚えていません。
まあでもこうやって気軽に使えて、pdfにもできてグラフの種類も豊富で、取り敢えずグラフ関係はこれでよしと思えるくらい機能充実なのが、支持される理由なのかなーと思っています。
それではまた。



